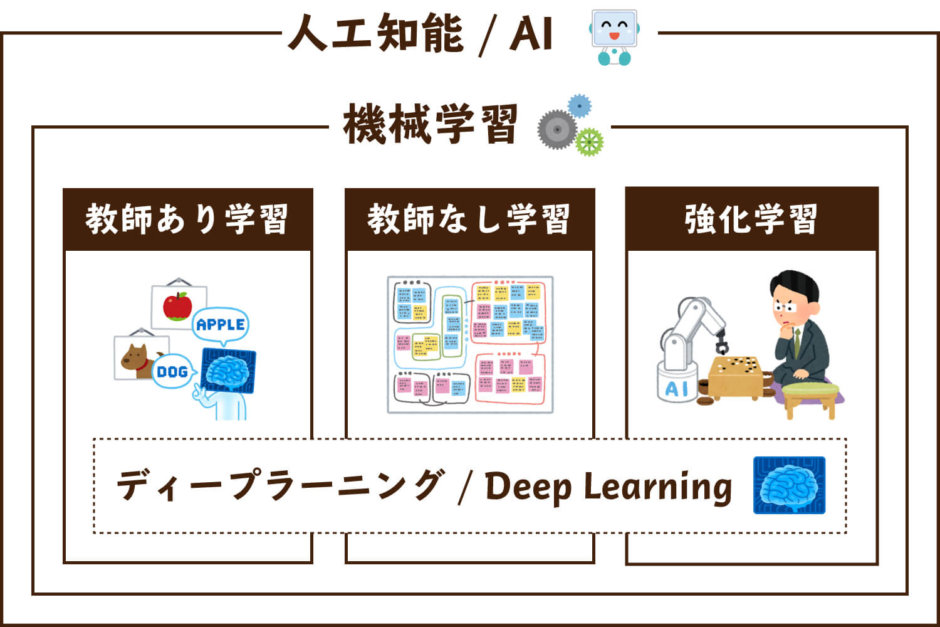
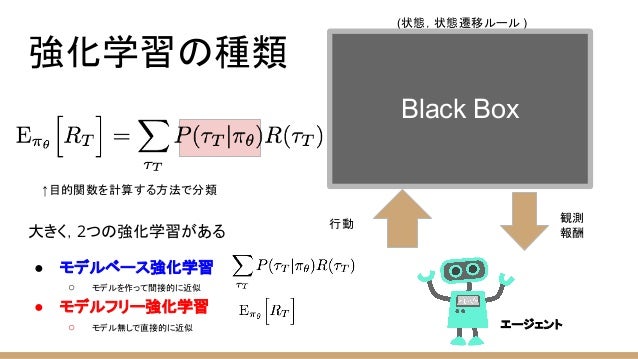
強化学習(RL)において、モデルフリーアルゴリズム(model-free algorithm)あるいはモデル無しアルゴリズムとは、マルコフ決定過程(MDP)の環境ダイナミクス(遷移確率分布と報酬分布)を推定しないアルゴリズムのことである。遷移確率分布と報酬分布は、しばしばまとめて環境(またはMDP)の「モデル」と呼ばれるため、「モデルフリー」という名前が付けられている。モデルフリー強化学習アルゴリズムは、「明示的な」試行錯誤アルゴリズムと考えることができる。モデルフリーアルゴリズムの典型的な例としては、モンテカルロ法(MC法)、SARSA法、Q学習がある。
モンテカルロ推定は、多くのモデルフリーアルゴリズムの中心的な要素である。基本的に一般化方策反復法(GPI)の具体化であり、方策評価(PEV)と方策改善(PIM)の二つが交互に繰り返される。このフレームワークでは、各方策はまず対応する価値関数によって評価される。次に、評価に基づいて、より良い方策を作成するために貪欲(greedy)探索を行う。モンテカルロ推定は、主に方策評価の最初のステップに適用される。もっとも単純なものは、現在の方策の有効性を判断するために、収集されたすべてのサンプルの収益を平均する。より多くの経験が蓄積されるにつれて、大数の法則により推定値は真の値に収束する。したがって、モンテカルロ法による方策評価は、環境ダイナミクスに関する事前の知識を必要としない。代わりに、(現実またはシミュレートされた)環境との相互作用から生成される経験(つまり、状態、行動、報酬のサンプル)のみが必要となる。
価値関数の推定は、モデルフリーアルゴリズムにとって重要である。MC法とは異なり、時間差分法(TD法)は既存の価値推定値を再利用(ブートストラッピング)することでこの関数を学習する。TD学習は、最終結果を待たずに、エピソードの部分的な軌跡から学習する能力を持つ。また、現在の状態の関数として将来の収益を近似することもできる。MCと同様に、TDは環境ダイナミクスに関する事前の知識なしに、経験のみを使用して価値関数を推定する。TDの利点は、現在の推定値に基づいて価値関数を更新できるという点にある。したがって、TD学習アルゴリズムは、不完全なエピソードまたは継続的なタスクから段階的に学習できるが、MCはエピソード単位で実装する必要がある。
モデルフリー深層強化学習アルゴリズム
モデルフリーアルゴリズムは、ランダムな方策から始めて、Atariゲーム、StarCraft、囲碁など、多くの複雑なタスクで人間を超えるパフォーマンスを達成できる。深層ニューラルネットワークは、最近の人工知能のブレークスルーを担っており、RLと組み合わせることで、Google DeepMindのAlphaGoなどの人間を超えるエージェントを作成できる。主流のモデルフリーアルゴリズムには、DQN(深層Q学習)、Rainbow、TRPO(信頼領域方策最適化)、PPO(近接方策最適化)、A3C(非同期アドバンテージ・アクター・クリティック法)、A2C(同期アドバンテージ・アクター・クリティック法)、DDPG(深層決定的方策勾配法)、TD3(二重遅延型深層決定的方策勾配法)、SAC(ソフト・アクター・クリティック法)、DSAC(分布ソフト・アクター・クリティック法)などがある。
脚注
出典